Using UTF-8 (Unicode) on FreeBSD
May 9, 2011 · Benjamin Lee · freebsd · unicode
Unicode is a set of character encodings that are compatible with the Universal Coded Character Set (UCS) defined by ISO/IEC 10646. Unicode was designed to replace all previous character encodings such as the American Standard Code for Information Interchange (US-ASCII) and ISO/IEC 8859.
UTF-8, which is also described in RFC 3629, is a variable-length Unicode character encoding that is backwards compatible with US-ASCII. That is, all US-ASCII characters have the same encoding under both US-ASCII and UTF-8. Due to the widespread use of US-ASCII in computing environments, this backwards compatibility makes UTF-8 convenient to deploy and therefore a popular choice for multilingual computing environments.
FreeBSD, like many UNIX-based operating systems, is unfortunately not configured to use UTF-8 by default. This sometimes causes confusion about whether Unicode is supported on FreeBSD. Fortunately, it is easy to enable UTF-8 on FreeBSD.
Determine the appropriate UTF-8 locale for your language and country. locale(1) can be used to print the names of all available locales.
locale -a | grep '\.UTF-8$'
Update the charset, lang, and setenv attributes in login.conf(5). It is recommended that LC_COLLATE be set to C because some programs still require ASCII ordering in order to function correctly.
To enable UTF-8 on a system-wide basis, update the default login class in /etc/login.conf.
blee@eclipse ~ $ diff -u /usr/src/etc/login.conf /etc/login.conf --- /usr/src/etc/login.conf 2011-03-10 13:48:59.000000000 -0800 +++ /etc/login.conf 2011-05-08 16:44:01.000000000 -0700 @@ -26,7 +26,7 @@ :passwd_format=md5:\ :copyright=/etc/COPYRIGHT:\ :welcome=/etc/motd:\ - :setenv=MAIL=/var/mail/$,BLOCKSIZE=K,FTP_PASSIVE_MODE=YES:\ + :setenv=MAIL=/var/mail/$,BLOCKSIZE=K,FTP_PASSIVE_MODE=YES,LC_COLLATE=C:\ :path=/sbin /bin /usr/sbin /usr/bin /usr/games /usr/local/sbin /usr/local/bin ~/bin:\ :nologin=/var/run/nologin:\ :cputime=unlimited:\ @@ -44,7 +44,9 @@ :pseudoterminals=unlimited:\ :priority=0:\ :ignoretime@:\ - :umask=022: + :umask=022:\ + :charset=UTF-8:\ + :lang=en_US.UTF-8: #To enable UTF-8 on a per-user basis, update ~/.login_conf. This is useful on servers that you do not administer and therefore cannot make system-wide changes.
blee@eclipse ~ $ cat ~/.login_conf me:\ :charset=UTF-8:\ :lang=en_US.UTF-8:\ :setenv=LC_COLLATE=C:
If /etc/login.conf was modified, run cap_mkdb(1) to rebuild the login class capabilities database.
sudo cap_mkdb /etc/login.conf
Exit all existing sessions that have the old locale settings.
Verify that the new settings took effect by running locale(1).
blee@eclipse ~ $ locale LANG=en_US.UTF-8 LC_CTYPE="en_US.UTF-8" LC_COLLATE=C LC_TIME="en_US.UTF-8" LC_NUMERIC="en_US.UTF-8" LC_MONETARY="en_US.UTF-8" LC_MESSAGES="en_US.UTF-8" LC_ALL=
If applicable, make application-specific configuration changes to enable UTF-8. Note that this has become increasingly unnecessary as applications have begun respecting locale settings.
Restart all applications that were started with the old locale settings.
Finally, here is the obligatory screenshot.
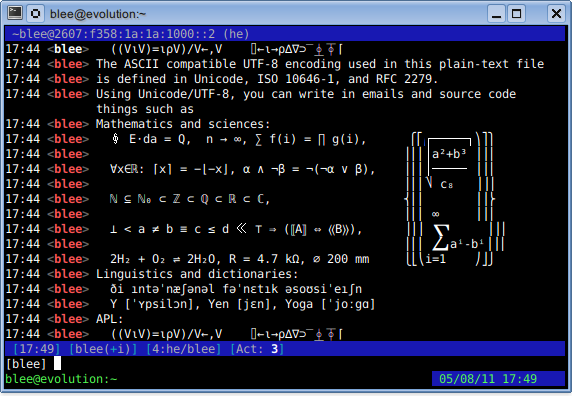
An excerpt from Markus Kuhn's Unicode/UTF-8 demo in Irssi running in GNU Screen over OpenSSH in Konsole.
For additional reading I recommend the UTF-8 and Unicode FAQ for Unix/Linux, the Localization - I18N/L10N Usage and Setup chapter of the FreeBSD Handbook, Using UTF-8 with Gentoo, and the Gentoo Linux Localization Guide.